
Exponential Backoff Algorithm
![]() · 4 min
· 4 min
Introduction to the Exponential Backoff Algorithm: Its Purpose, When, and How to Use It
Handling 429 Errors: When ‘Too Many Requests’ Calls for Patience (and Math)
Purpose
An exponential backoff algorithm is a method used to delay the execution attempts of a piece of code in response to temporary errors or resource limitations. The delay increases exponentially with each retry, helping to reduce the load on the system or service being accessed, and allowing time for transient issues to resolve before the next attempt is made.
When Use This Algorithm?
The exponential backoff algorithm should be used when the execution of a piece of code triggers an error that can be considered temporary (short-term). In such cases, it may be appropriate to retry the code execution.
For a concrete example, consider requests made to a DynamoDB database. Whether using provisioned capacity or on-demand capacity, Amazon’s service imposes limits to prevent resource overconsumption. These limits are expressed as a number of requests per second. Once the threshold is exceeded, the service returns a “Throttle Request” error. In such scenarios, it is highly relevant to use exponential backoff to delay requests and reduce pressure on the service.
How to use this Algorithm?
Implementing this algorithm simply involves adapting the script’s behavior based on the HTTP status code returned by the server following a request.
💡 Important Note: In all cases, the use of such an algorithm requires implementing a limit to cap the number of retries in order to avoid an infinite loop.
Here is an example in PHP:
<?php
declare(strict_types=1);
interface HttpClientInterface
{
public function get(string $url): HttpResponseInterface;
public function post(string $url, array $body): HttpResponseInterface;
}
interface HttpResponseInterface
{
public function getCode(): int;
}
readonly class ServiceGateway
{
public function __construct(private HttpClientInterface $httpClient)
{
}
public function __invoke(string $url): HttpResponseInterface
{
$retries = 0;
$maxRetry = 5;
do {
if ($retries > 0) {
$this->wait($retries);
}
$response = $this->httpClient->get($url);
} while ($response->getCode() === 429 && $retries++ < $maxRetry);
if ($response->getCode() === 429) {
throw new \Exception('Too many requests');
}
return $response;
}
private function wait(int $retries): void
{
$waitTime = \pow(2, $retries) * 100;
\usleep($waitTime * 1000);
}
}
In this example, the __invoke method takes the URL of an external API as a parameter. This URL is used to perform a GET request against the API.
A specific check is performed on the HTTP 429 status code — this code returned by the remote server indicates that it can no longer process the request because too many requests have been sent.
In such cases, it makes sense to throttle the request and replay it. The throttling is achieved here via the usleep() instruction, where the wait time between two attempts grows exponentially based on the number of attempts made.
If the maximum number of retries ($maxRetry) has been reached, the do{}while(); exit condition is satisfied and an exception is thrown to indicate that the API call could not be completed.
In the graph below we can see the waiting time evolution depending on retry attempts :
\[2^{retries} \cdot 100\]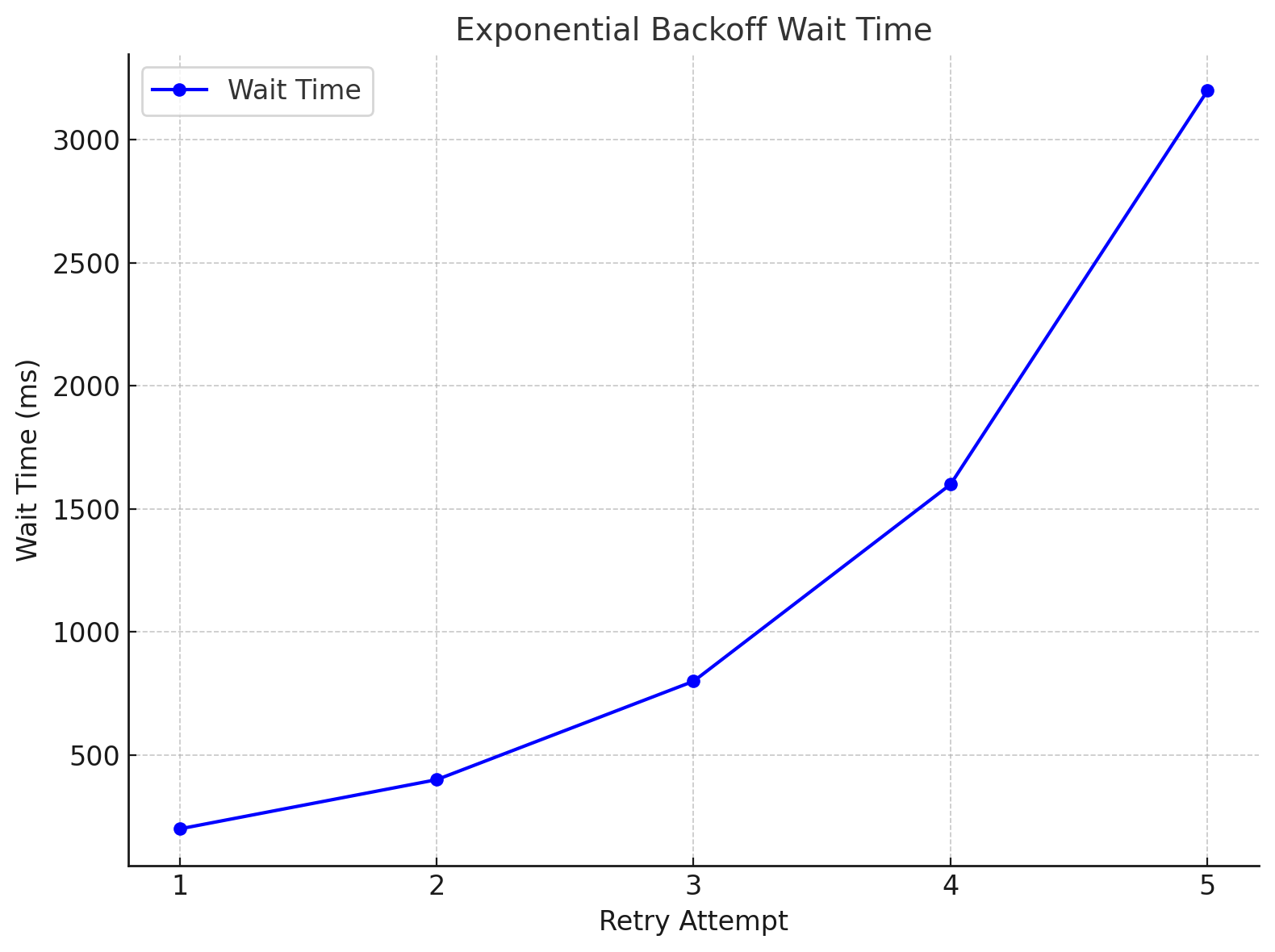
In the worst case 5 requests have to be sent and the total script waiting time will be :
\[S = \sum_{n=1}^{5} 2^n \cdot 100 = 6200 ms\]Conclusion
In this article we’ve seen the purpose of the exponential backoff algorithm, when and how to use it. It’s an important principle to keep in mind when consuming APIs.