
Algorithme d'exponentiel backoff
![]() · 5 min
· 5 min
Introduction à l’algorithme d’exponentiel backoff : utilité, quand et comment l’utiliser
Gérer les erreurs 429 : quand “Trop de requêtes” appelle à la patience (et aux mathématiques)
Utilité
Un algorithme d’exponentiel backoff est une méthode permettant de temporiser les tentatives d’exécution d’un bout de code en réponse à des erreurs temporaires ou à des limitations de ressources. Le délai augmente de façon exponentielle à chaque tentative, ce qui permet de réduire la charge sur le système ou le service sollicité, et de laisser le temps aux problèmes transitoires de se résoudre avant la prochaine tentative.
Quand utiliser cet algorithme ?
L’algorithme d’exponential backoff est à utiliser lorsque l’exécution d’un bout de code provoque une erreur pouvant être considérée comme étant temporaire (à court terme). Dans ce cas, il peut être pertinent de relancer l’exécution du code.
Prenons comme exemple concret les requêtes sur une base DynamoDB. Que ce soit au niveau d’une capacité provisionnée ou à la demande, le service d’Amazon impose des limites permettant d’éviter la sur-consommation des ressources. La limite se présente sous forme d’un nombre de requêtes par seconde. Une fois le seuil franchi, le service retourne alors une erreur de type “Throttle Request”. Dans ce cas, il est tout à fait pertinent d’utiliser l’exponential backoff afin de temporiser les requêtes et ainsi de diminuer la pression sur le service.
Comment utiliser cet algorithme ?
La mise en œuvre de cet algorithme consiste simplement à adapter le comportement du script en fonction du code de statut HTTP retourné par le serveur suite à une requête.
💡 Point d’attention : dans tous les cas, l’utilisation d’un tel algorithme nécessite la mise en place d’une limite permettant de caper le nombre de tentatives afin d’éviter une boucle infinie.
Voici un exemple en PHP :
<?php
declare(strict_types=1);
interface HttpClientInterface
{
public function get(string $url): HttpResponseInterface;
public function post(string $url, array $body): HttpResponseInterface;
}
interface HttpResponseInterface
{
public function getCode(): int;
}
readonly class ServiceGateway
{
public function __construct(private HttpClientInterface $httpClient)
{
}
public function __invoke(string $url): HttpResponseInterface
{
$retries = 0;
$maxRetry = 5;
do {
if ($retries > 0) {
$this->wait($retries);
}
$response = $this->httpClient->get($url);
} while ($response->getCode() === 429 && $retries++ < $maxRetry);
if ($response->getCode() === 429) {
throw new \Exception('Too many requests');
}
return $response;
}
private function wait(int $retries): void
{
$waitTime = \pow(2, $retries) * 100;
\usleep($waitTime * 1000);
}
}
Dans cet exemple, la méthode __invoke prend en paramètre l’URL d’une API externe. Cette URL est utilisée afin de réaliser un GET sur l’API.
Un test particulier est réalisé sur le code HTTP 429 — ce code retourné par le serveur distant indique que celui-ci ne peut plus traiter la demande car trop de requêtes ont été envoyées.
Dans ce cas, il est pertinent de temporiser la requête et de la rejouer. La temporisation est ici réalisée via l’instruction usleep(), le temps d’attente entre deux tentatives croît de façon exponentielle en fonction du nombre de tentatives effectuées.
Dans le cas où le nombre limite de tentatives ($maxRetry) a été atteint, la condition de sortie du do{}while(); est alors satisfaite et une exception est levée afin d’indiquer que l’appel API n’a pas pu être réalisé.
Dans le graphique ci-dessous, on peut observer l’évolution du temps d’attente en fonction du nombre de tentatives :
\[2^{retries} \cdot 100\]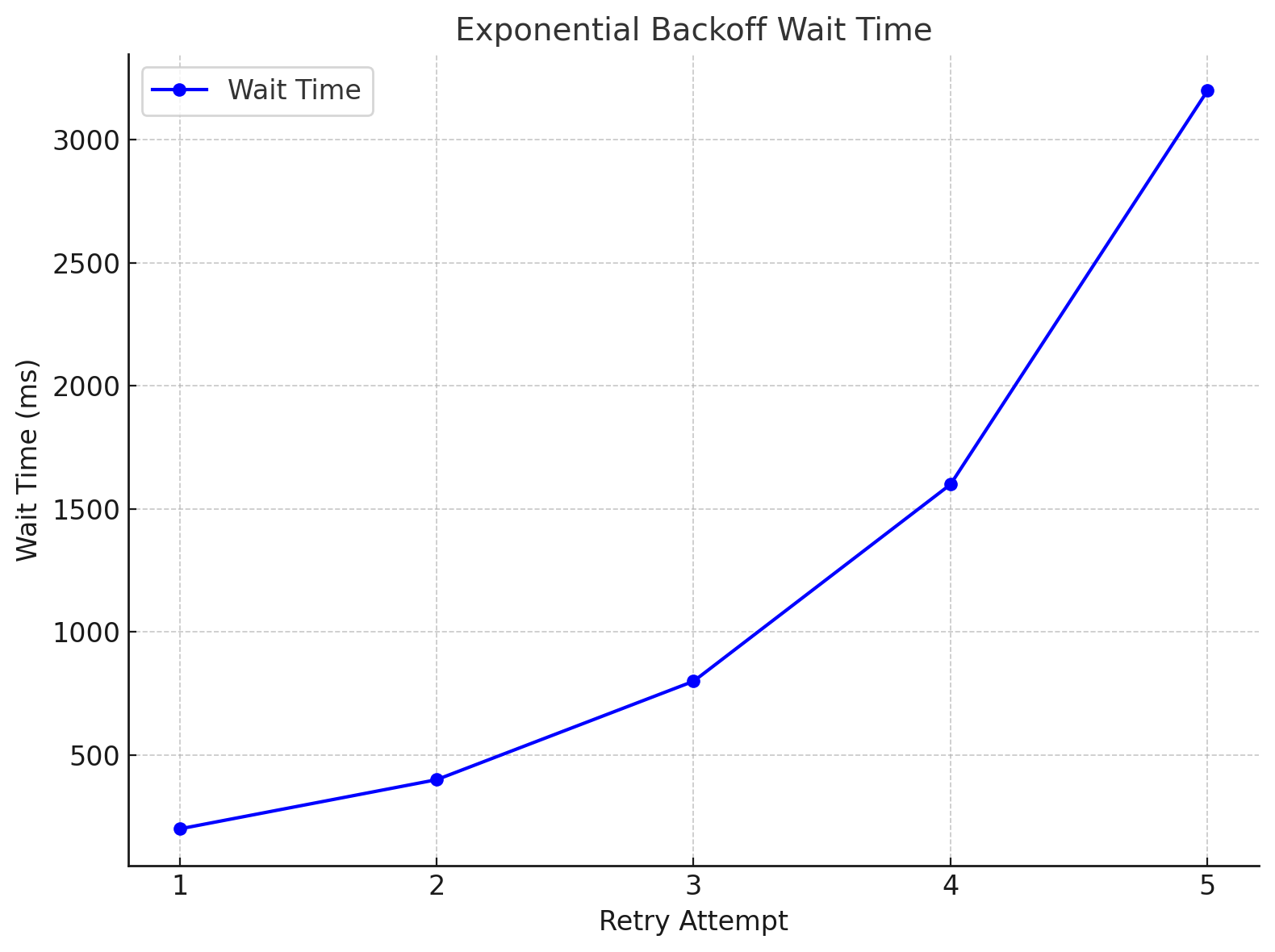
Dans le pire des cas, 5 requêtes doivent être envoyées et le temps d’attente total du script sera :
\[S = \sum_{n=1}^{5} 2^n \cdot 100 = 6200 ms\]Conclusion
Dans cet article, nous avons vu l’utilité de l’algorithme d’exponentiel backoff, quand et comment l’utiliser. C’est un principe important à garder en tête lors de la consommation d’APIs.