Postgresql Pagination
![]() · 5 min
· 5 min
PostgreSQL Pagination — Cost Analysis
OFFSET scans and discards rows
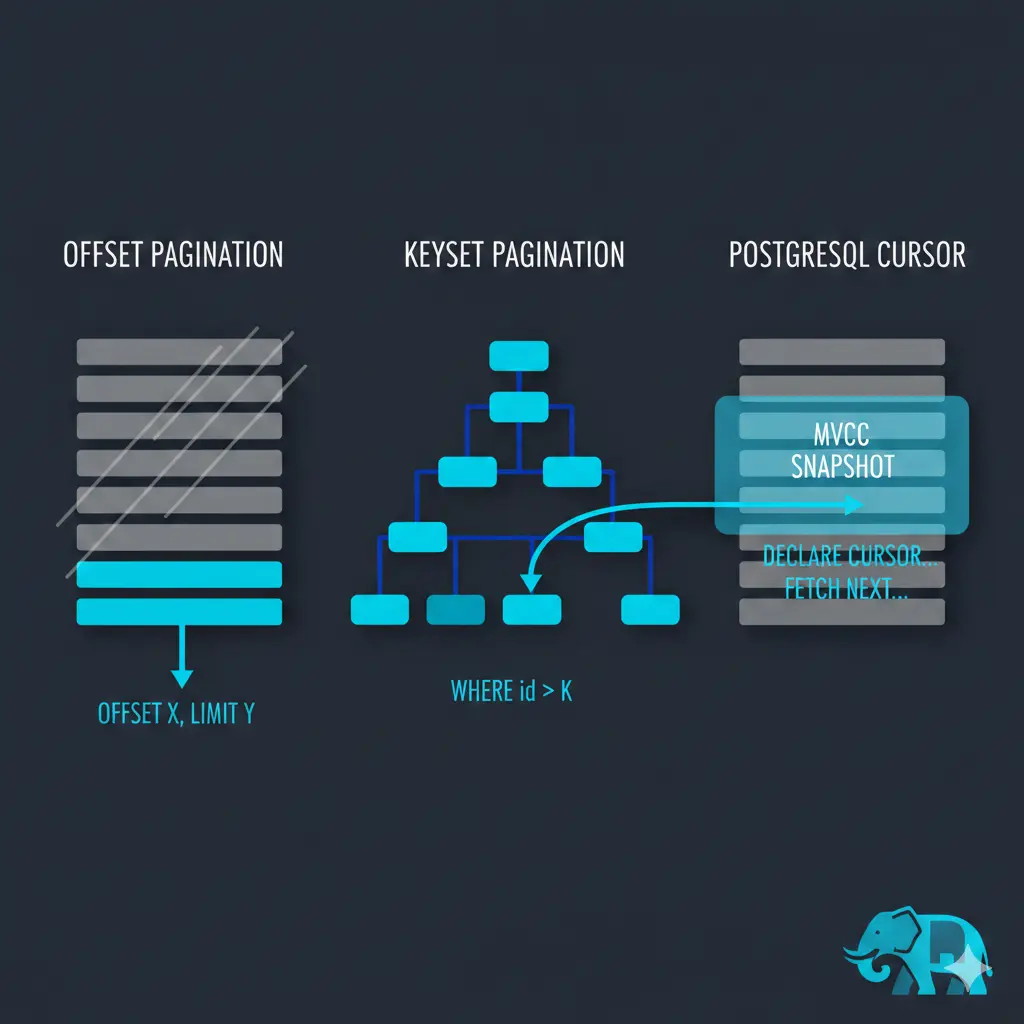
When querying PostgreSQL with OFFSET 50000, PostgreSQL has no way to “jump” to position 50,000 in a result set. It must traverse rows in order and count through the first 50,000 before returning results.
With a sequential scan: reads and counts through the first 50,000 rows, then returns the next N rows.
With an index scan: traverses index entries one by one, skipping the first 50,000 matching entries. Cheaper than full row reads, but still cannot skip to position N directly.
The cost of OFFSET is O(n) — it grows linearly with the offset value.
Why keyset pagination is better
-- Slow at high offsets:
SELECT * FROM posts ORDER BY created_at LIMIT 10 OFFSET 50000;
-- Always fast — uses the index to jump directly to the cursor position in O(log n):
SELECT * FROM posts WHERE created_at < :last_seen_cursor ORDER BY created_at DESC LIMIT 10;
Total cost to iterate an entire dataset
Keyset pagination
For a dataset of n rows with page size k:
- Number of pages:
n/k - Per page cost: index B-tree lookup
O(log n)+ readkrowsO(k)
Total cost:
(n/k) × (log n + k)
= (n/k) × log n + (n/k) × k
= (n/k) × log n + n
= O(n + (n/k) × log n)
Behavior at the extremes:
Page size k |
Dominant term | Simplifies to |
|---|---|---|
k = 1 |
n log n |
O(n log n) |
k = √n |
both equal | O(n) |
k = n |
n |
O(n) |
Offset pagination
Each page i scans i×k rows:
k + 2k + 3k + ... + n = k × (1 + 2 + ... + n/k) ≈ n²/(2k) = O(n²/k)
With a cursor
A PostgreSQL cursor maintains traversal state server-side. The index (or sequential scan) is set up once at DECLARE, then each FETCH continues from where it left off — no repeated index lookups.
DECLARE cur CURSOR FOR SELECT * FROM posts ORDER BY created_at;
FETCH 10 FROM cur; -- index lookup once: O(log n), then reads 10 rows
FETCH 10 FROM cur; -- just continues traversal: O(k)
FETCH 10 FROM cur; -- O(k)
Total cost:
O(log n) + n × O(1) = O(n)
How PostgreSQL ensures order and prevents duplicates with a cursor
Order
The ORDER BY clause in the DECLARE statement drives this. If a matching index exists, PostgreSQL sets up an index scan on it once — the index is already physically sorted, so the cursor just walks it sequentially. Each FETCH advances a pointer along that index scan. No re-sorting, no re-scanning from the start.
No duplicates
PostgreSQL uses MVCC (Multi-Version Concurrency Control). When you DECLARE a cursor inside a transaction, PostgreSQL captures a snapshot of the database state at that moment. Every subsequent FETCH reads from that same frozen snapshot, regardless of concurrent inserts, updates, or deletes happening on the table.
This means:
- rows inserted after
DECLAREare invisible to the cursor - rows deleted after
DECLAREare still visible (as they existed in the snapshot) - no row can appear twice because the cursor advances a position pointer server-side — it never re-reads already-fetched positions
The trade-off this creates
This is exactly why cursors require holding an open transaction for their entire lifetime. The snapshot must stay alive until the cursor is closed (CLOSE cur or end of transaction). The longer the transaction, the longer PostgreSQL must retain old row versions for other concurrent readers — which is why long-running cursors can cause table bloat and interfere with VACUUM on busy tables.
Summary
| Strategy | Full iteration cost | Index lookups |
|---|---|---|
| Offset pagination | O(n²/k) |
0 (but scans rows) |
| Keyset pagination | O(n + (n/k) × log n) |
n/k |
| Cursor | O(n) |
1 |
Cursor trade-offs
Cursors are optimal for full iteration but come with constraints:
- Hold an open connection for the duration
- Hold a transaction (and potentially locks/snapshot resources)
- Not suitable for stateless APIs (e.g. HTTP endpoints between requests)
Use cursors for: batch jobs, ETL, data exports. Use keyset pagination for: user-facing pagination over HTTP.